Papers
Table of contents
- Towards Responsible AI: A Design Space Exploration of Human-CenteredArtificial Intelligence User Interfaces to Investigate Fairness
- Towards Expert-Level Medical Question Answering with Large Language Models
- Explaining Machine Learning Models with Interactive Natural Language Conversations Using TalkToModel
- LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Towards Responsible AI: A Design Space Exploration of Human-CenteredArtificial Intelligence User Interfaces to Investigate Fairness
They made a UI (FairHIL) to support human-in-the-loop fairness investigations, and describe how the UI can be generalized to other use cases.
They address that most UIs that investigate fairness are focussed on enabling data scientists or ML experts to assess their models, rather than involving domain experts or end-users.
Towards Expert-Level Medical Question Answering with Large Language Models
Med-PaLM 2 is developed using a combination of an imporved base LLM (PaLM 2), medical domain-specific finetuning and a novel prompting strategy that enabled imporved medical reasoning. They also introduce ensemble refinement as a new prompting strategy to improve LLM reasoning.
They use two human evaluations:
- A pairwise ranking evaluation of model and physician answers to consumer medical questions along nine clinically relevant dimensions.
- A phycisian assessment of model responses on two newly introduced adversarial testing datasets designed to probe the limits of LLMs.
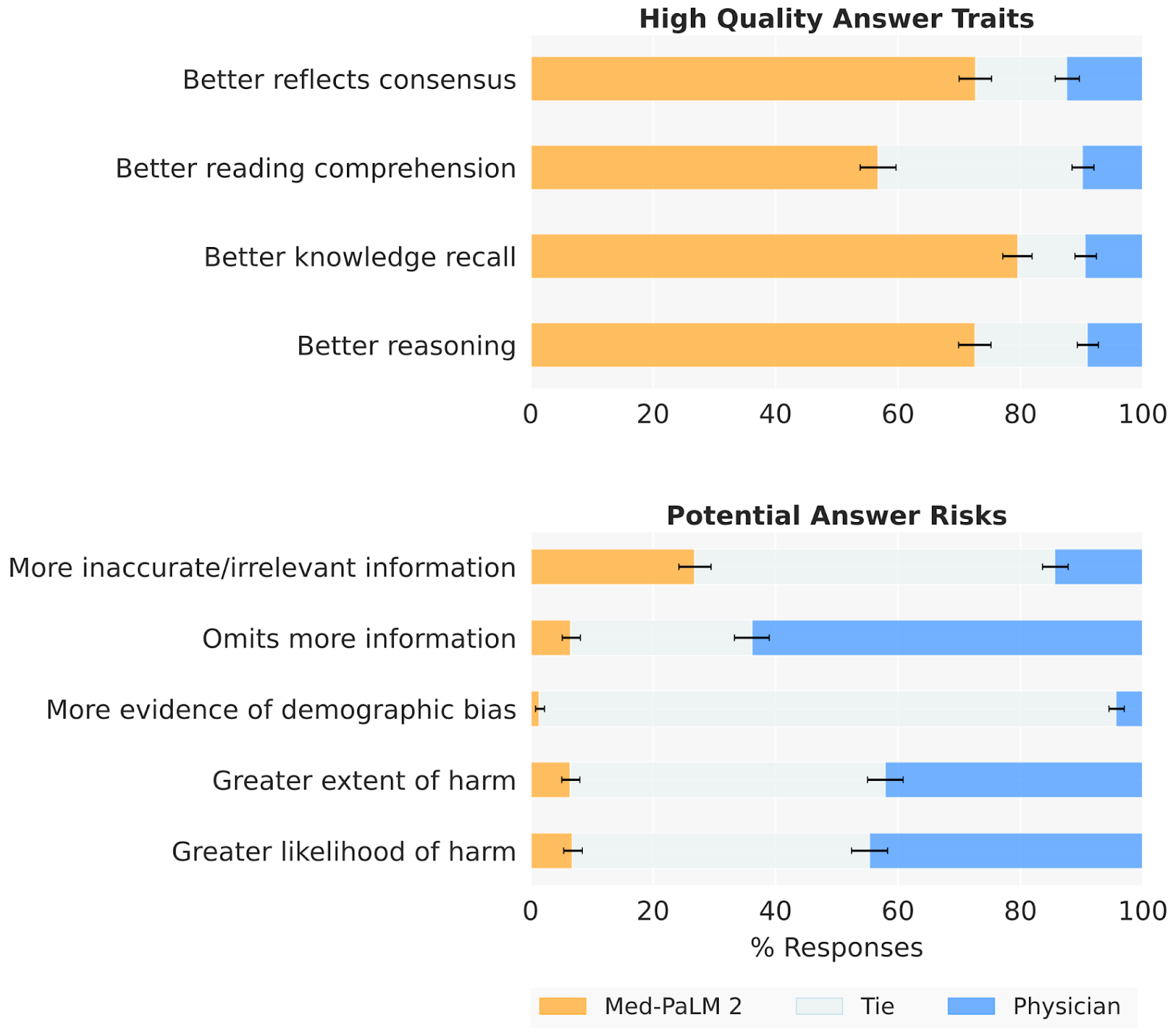
In pairwise comparative ranking of 1066 consumer medical questions, phycisians preferred Med-PaLM 2 answers to those produced by physicians on eight out of nine axes pertaining to clinical relevance. Med-PaLM 2 also outperformed the best LLM baseline on all axes.
Prompting strategies:
- Few-shot prompting: This involves prompting an LLM by prepending example inputs and output before the final input.
- Chain-of-thought (CoT): This involves augmenting each few-shot example in a prompt with a step-by-step explanation towards the final answer. This enables a LLM to condition on its own intermediate output in multi-step problems. The medical questions explored in this study often involve complex multi-step reasoning, making them a good fit for CoT prompting. They crafted CoT prompts to provide clear demonstrations on how to appropriately answer the given medical question.
- Self-consistency (CS): This strategy imporves performance on multiple-choice benchmarks by sampling multiple explanations and answers from the model. The final answer is the one with the majority (or plurality) vote. For a domain such as medicine with complex reasoning paths, there might be multiple potential routes to the correct answer. Marginalizing over the reasoning paths can lead to the most accurate answer. The self-consistency prompting strategy led to particularly strong improvements. Here they performed SC with 11 samplings using CoT prompting.
- Ensemble refinement (ER): ER builds on other techniques that involve conditioning an LLM on its own generations before producing a final answer, including chain-of-thought prompting and self-Refine
Explaining Machine Learning Models with Interactive Natural Language Conversations Using TalkToModel
The system, named TalkToModel, addresses the challenges faced by practitioners in understanding and interpreting machine learning models. It consists of three key components:
- A natural language interface for engaging in conversations, making machine learning model explainability highly accessible.
- A dialogue engine that adapts to any tabular model and dataset, interprets natural language, maps it to appropriate explanations, and generates text responses.
- An execution component that constructs the explanations.
The paper reports that TalkToModel understands user inputs on novel datasets and models with high accuracy, demonstrating the system’s capacity to generalize to new situations. In real-world evaluations with humans, 73% of healthcare workers (e.g., doctors and nurses) agreed they would use TalkToModel over baseline point-and-click systems for explainability in a disease prediction task, and 85% of machine learning professionals agreed TalkToModel was easier to use for computing explanations.