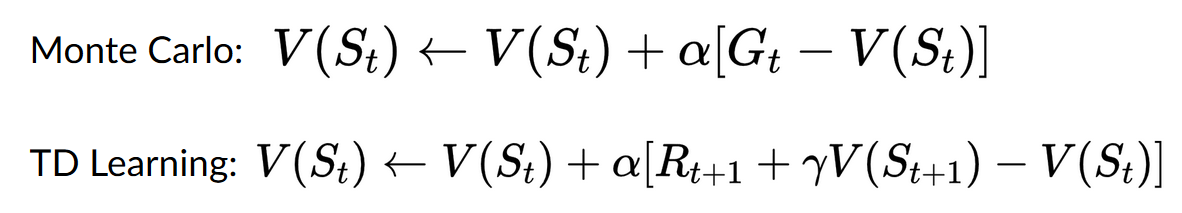The big picture
The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by interacting with it (through trial and error) and receiving rewards (negative or positive) as feedback for performing actions.
Definition
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
The RL process
- Our Agent receives state \(S_0\) from the Environment
- Based on that state \(S_0\), the Agent takes action \(A_0\)
- Environment goes to a new state \(S_1\)
- The environment gives some reward \(R_1\) to the Agent
State vs. Obsevation
- State s: is a complete description of the state of the world (there is no hidden information). In a fully observed environment.
- Observation o: is a partial description of the state. In a partially observed environment.
Action Space
- Discrete space: the number of possible actions is finite.
- Continuous space: the number of possible actions is infinite.
Reward and Discount
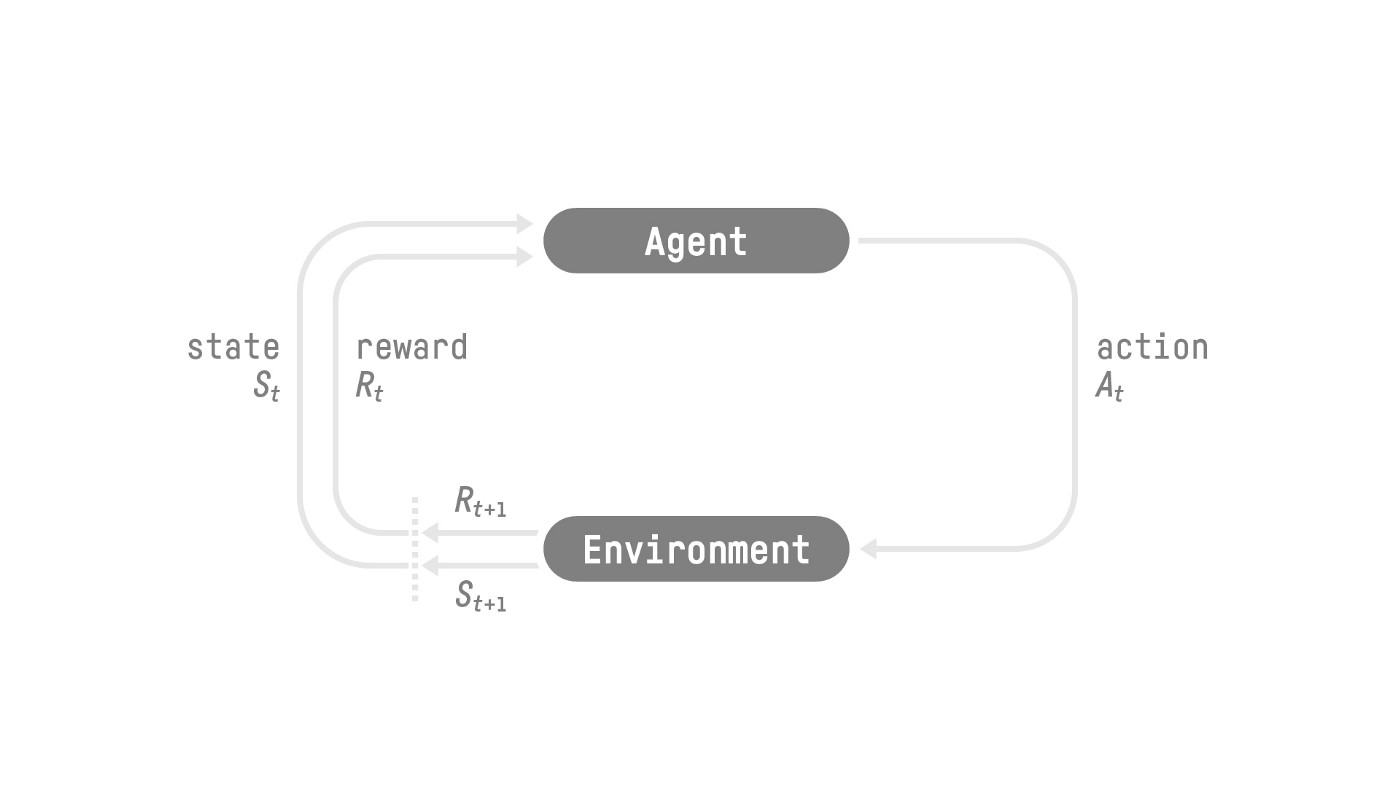
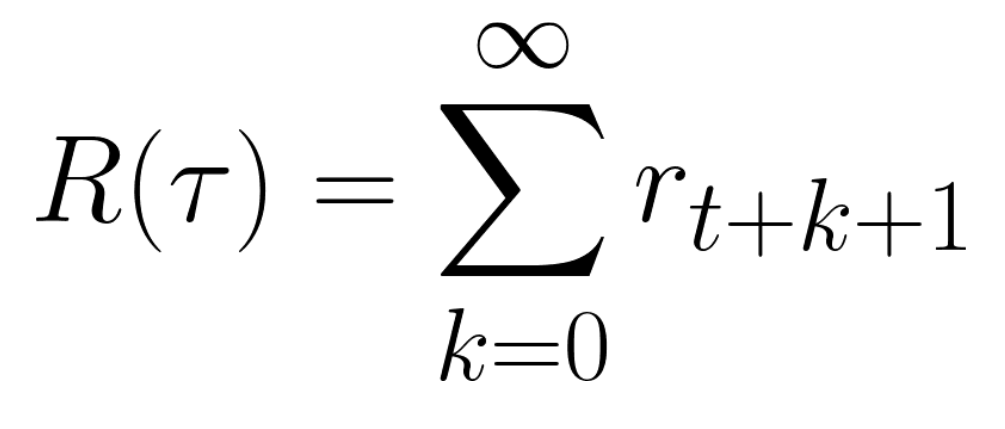 However, in reality, we can’t just add them like that. The rewards that come sooner (at the beginning of the game) are more likely to happen since they are more predictable than the long-term future reward.
However, in reality, we can’t just add them like that. The rewards that come sooner (at the beginning of the game) are more likely to happen since they are more predictable than the long-term future reward.
To discount the rewards, we proceed like this:
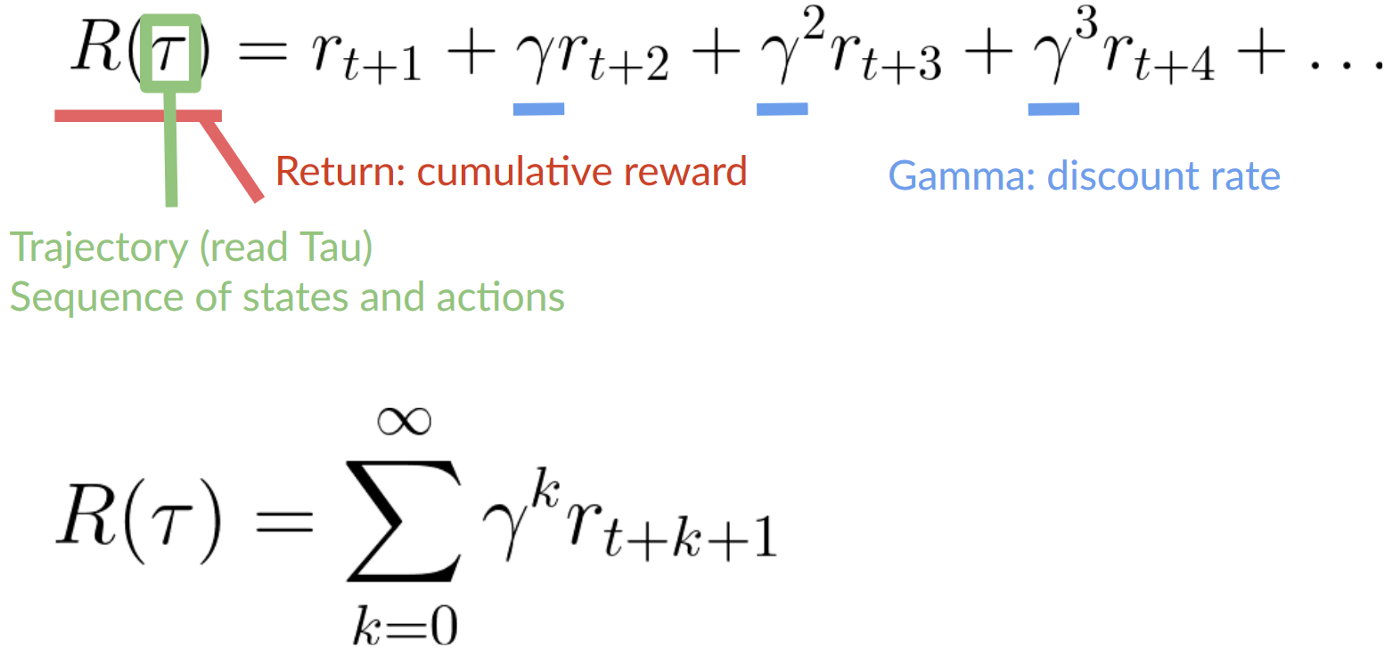
- We define a discount rate called \(\gamma\). It must be between 0 and 1. Most of the time between 0.99 and 0.95.
- The larger \(\gamma\), the smaller the discount. This means our agent cares more about the long-term reward.
- On the other hand, the smaller \(\gamma\), the bigger the discount. This means our agent cares more about the short term reward (the nearest cheese). 2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, so the future reward is less and less likely to happen.
Type of Tasks
- Episodic task in this case, we have a starting point and an ending point (a terminal state). This creates an episode: a list of States, Actions, Rewards, and new States.
- Continuing tasks are tasks that continue forever (no terminal state). In this case, the agent must learn how to choose the best actions and simultaneously interact with the environment.
Exploration vs. Explotation
- Exploration is exploring the environment by trying random actions in order to find more information about the environment.
- Exploitation is exploiting known information to maximize the reward. We need to balance how much we explore the environment and how much we exploit what we know about the environment.
Solving RL problems
The Policy π is the brain of our Agent, it’s the function that tells us what action to take given the state we are. So it defines the agent’s behavior at a given time.
This Policy is the function we want to learn, our goal is to find the optimal policy π, the policy that maximizes expected return when the agent acts according to it. We find this π through training.
There are two approaches to train our agent to find this optimal policy π*:
- Directly, by teaching the agent to learn which action to take, given the current state: Policy-based Methods.
- Indirectly, teach the agent to learn which state is more valuable and then take the action that leads to the more valuable states: [[Value-Based Methods]]. Both can be learned with Monte Carlo (learns at the end of an episode) and Temporal Difference Learning (learns at each step)