What Is It?
Within an RND, we have two networks:
- A target network, f, with fixed, randomized weights, which is never trained. That generates a feature representation for every state.
- A prediction network, \(\hat{f}\), that tries to predict the target network’s output.
Because the target network parameters are fixed and never trained, its feature representation for a given state will always be the same. Instead of predicting the next state \(s_{t+1}\) given our current state \(s_t\) and action \(a_t\) as for Intrinsic Curiosity Module, the predictor network predicts the target’s network output for the next state.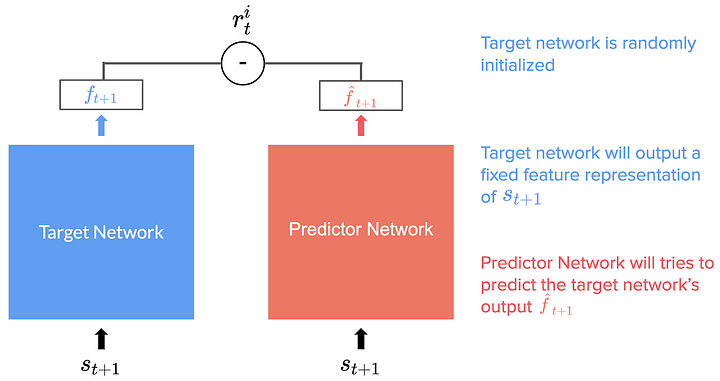
Therefore, each state \(s_{t+1}\) is fed into both networks, and the prediction network is trained to minimize the difference mean square error (between the target network’s output and the predictor network’s output). This is denoted by r in these formulas. This is yet another prediction problem: our random initialized neural network outputs are the labels, and the goal of our prediction is to find the correct label. This process distills a randomly initialized neural network (target) into a trained (predictor) network.
This is yet another prediction problem: our random initialized neural network outputs are the labels, and the goal of our prediction is to find the correct label. This process distills a randomly initialized neural network (target) into a trained (predictor) network.
If we go back to the Markov decision process formulation, we add a new step to calculate the intrinsic reward: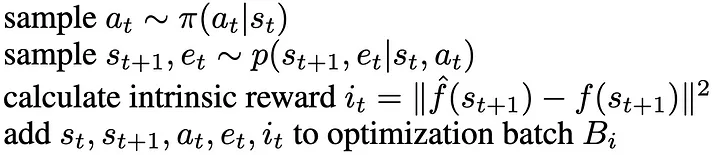
- Given the current state \(s_t\), we take an action \(a_t\) using our policy \(\pi\)
- We get the extrinsic reward \(r_t\) and the next state \(s_{t+1}\)
- Then we calculate the intrinsic reward \(ri_t\) using the formula above
Some Shared Similarities with ICM
Just like for Intrinsic Curiosity Module, when reaching previously visited states, the RND agent receives a small intrinsic reward (IR) because the target outputs are predictable, and the agent is disincentivized to reach them again. And when in an unfamiliar state, it makes poor predictions about the random network output, so the IR will be high.
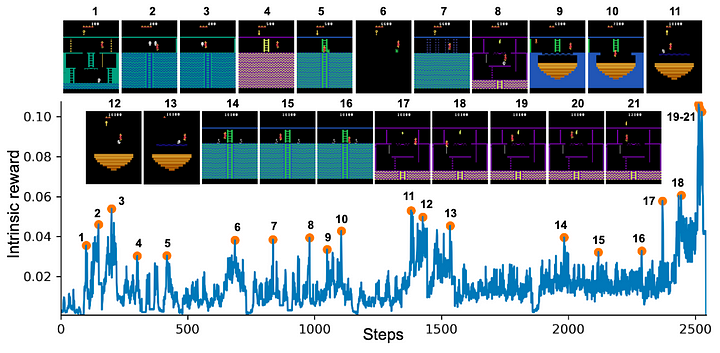 We can see on the experimentation of OpenAI on Montezuma’s Revenge that the spikes in the IR (or the prediction error) correspond to meaningful events:
We can see on the experimentation of OpenAI on Montezuma’s Revenge that the spikes in the IR (or the prediction error) correspond to meaningful events:
- Losing a life (2, 8, 10, 21)
- Escaping an enemy by a narrow margin (3, 5, 6, 11, 12, 13, 14, 15)
- Passing a difficult obstacle (7, 9, 18)
- Picking up an object (20, 21).
This implies that intrinsic reward is non-stationary: what’s new at a given time will become usual through time, as it will be visited more and more during training. This will have some consequences when we’ll implement our agent.
Overcoming Procrastination
Contrary to Intrinsic Curiosity Module, the RND agent no longer tries to predict the next state (the unpredictable next frame on the screen), but instead the state’s feature representation from the random network. By removing the dependence on the previous state, when the agent sees a source of random noise, it doesn’t get stuck.
Why? Because after enough training of states coming from stochastic elements from the environment (random spawning of objects, random movement of an element, etc.) , the prediction network is able to better predict the outputs of the target network.
As the prediction error decreases, the agent becomes less attracted to the noisy states than to other unexplored states. This reduces the Noisy-TV error.
But more importantly, beyond this theoretical concern (after all, most of our video game environments are largely deterministic), RND provides an architecture that is simpler to implement and easier to train than Intrinsic Curiosity Module since only the predictor network is trained.
While the noisy-TV problem is a concern in theory, for largely deterministic environments like Montezuma’s Revenge, we anticipated that curiosity would drive the agent to discover rooms and interact with objects.
Recap
To conclude, RND was able through exploration to achieve very good performance. But there is still a lot of work to be done.
As explained in the paper at the bottom RND is good enough for local exploration (exploring the consequences of short term decisions such as avoid skulls, take keys etc).
But global exploration is much more complex than that. And long relations (for instance, using a key that was found in the first room to open the last door) are still unsolved. This requires global exploration through long-term planning.
Implementation
For an implementation of RND check: RND Montezuma’s revenge Pytorch