Main idea
Q-Learning is an off-policy value-based method that uses a [ Temporal Difference Learning to train its action-value function. The Q comes from “the Quality” (the value) of that action at that state. Internally, our Q-function has a Q-table, a table where each cell corresponds to a state-action pair value. Think of this Q-table as the memory or cheat sheet of our Q-function.
Therefore, Q-function contains a Q-table that has the value of each-state action pair. And given a state and action, our Q-function will search inside its Q-table to output the value. 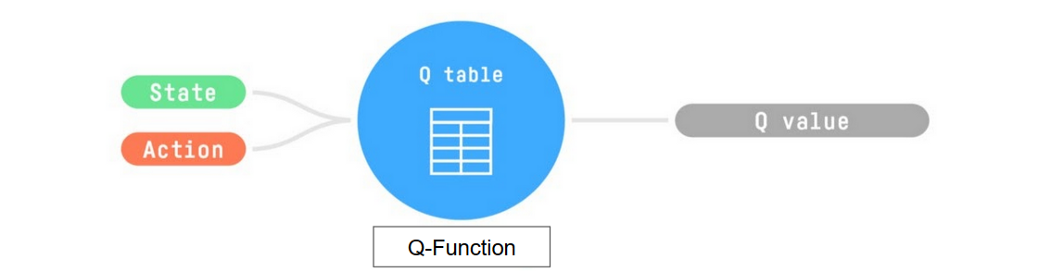
Pseudocode

- We need to initialize the Q-table for each state-action pair. Most of the time, we initialize with values of 0.
- Choose action using \(\epsilon-greedy\) strategy: The idea is that we define the initial epsilon \(\epsilon = 1.0\):
- With probability \(1-\epsilon\) : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With probability \(\epsilon\): we do exploration (trying random action). At the beginning of the training, the probability of doing exploration will be huge since \(\epsilon\) is very high, so most of the time, we’ll explore. But as the training goes on, and consequently our Q-table gets better and better in its estimations, we progressively reduce the epsilon value since we will need less and less exploration and more exploitation.
- Perform an action and get a reward and the next state
- Update \(Q(S_t, A_t)\)
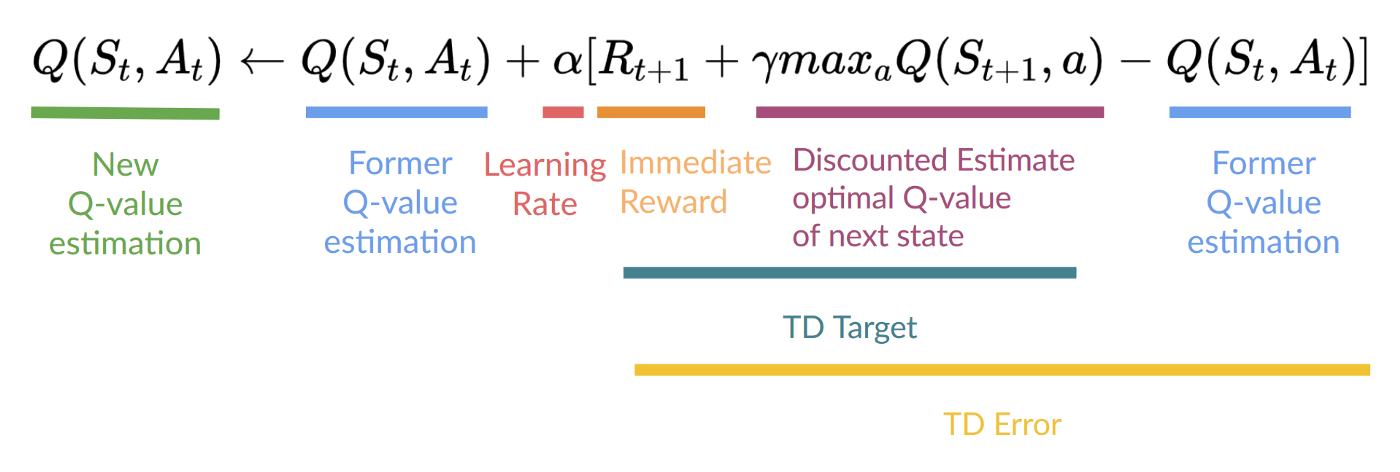
- Repeat for all episodes
Off-policy vs On-polic
- Off-policy: using a different policy for acting (inference) and updating (training).
- On-policy: using the same policy for acting and updating.