In value-based methods we train a value function that maps a state to the expected value of being at that state.
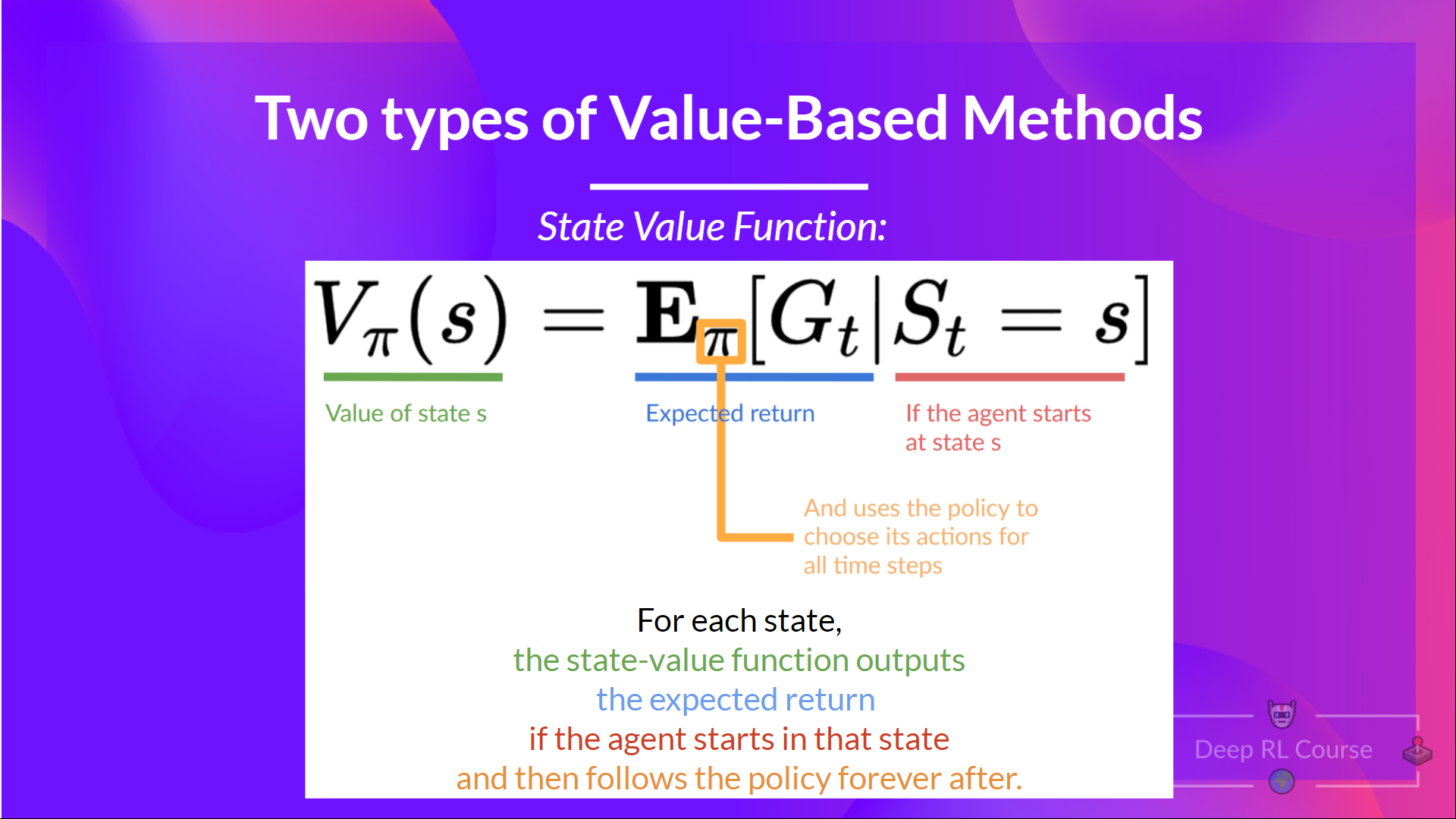
The value of a state is the expected discounted return the agent can get if it starts in that state, and then act according to our policy.
“Act according to our policy” just means that our policy is “going to the state with the highest value”. 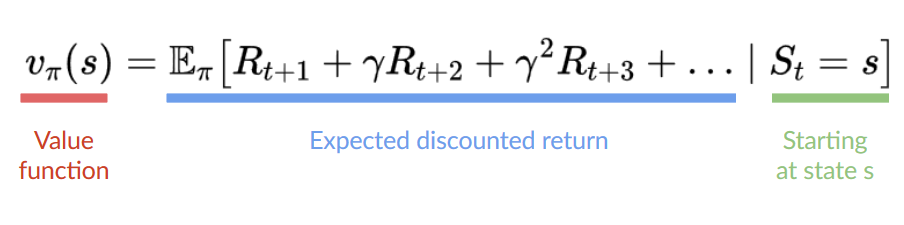
Two types of value-based methods
The problem is that it implies that to calculate EACH value of a state or a state-action pair, we need to sum all the rewards an agent can get if it starts at that state. This can be a computationally expensive process, and that’s where the [[Bellman equation]] comes to help us. 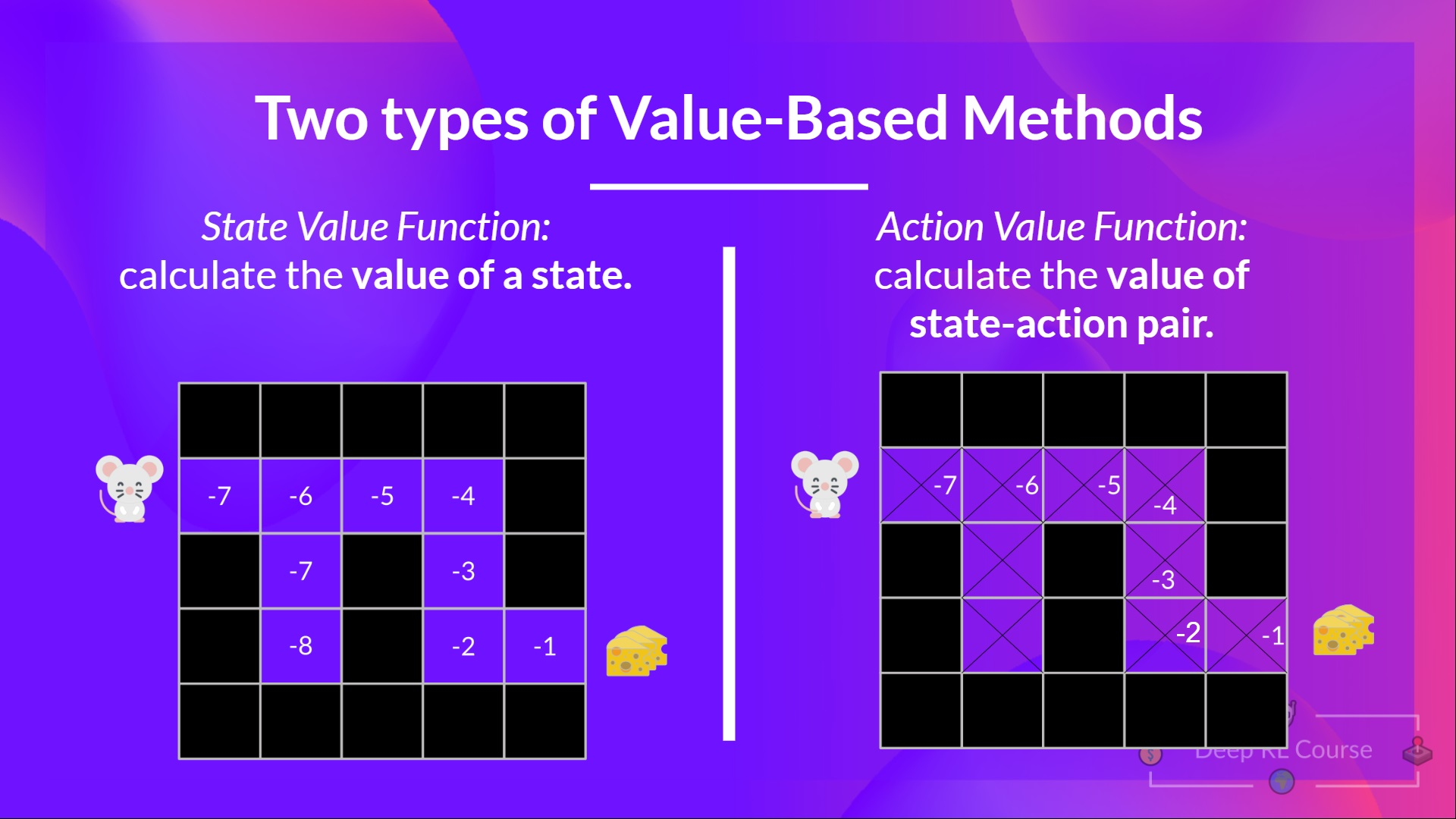
- State value function
- Action value function
